Amvera LLM Inference¶
Мы предоставляем доступ к нескольким большим языковым моделям через единый публичный API.
Аутентификация¶
Чтобы использовать Amvera LLM Inference API, необходимо пройти аутентификацию:
Для этого в ЛК, нужно зайти в любую модель в разделе LLM, и скопировать токен доступа.
Затем, при обращении к моделе, укажите токен доступа в заголовке Authorization в следующем формате: [Authorization: Bearer <access_token>]
API¶
Маршруты¶
Список актуальных маршрутов можно посмотреть в спецификации.
Поддерживаются форматы OpenAI для v1/chat/completions и Anthropic для v1/messages.
Стандарт OpenAI v1/responses пока поддерживает в beta режиме.
Модели¶
Используйте GET /v1/models или перейдите по этой ссылке, для того чтобы получить актуальный список моделей, а также информацию о том на каких маршрутах они доступны.
💡Совет:
Для использования в агентных системах написания кода, таких как:
Claude-Code, Codex, Aider, Cursor, Continue, Phind ; рекомендуется брать пакеты на 3М токенов и больше, и при оформлении ставить галочку автоподключения дополнительных пакетов, т.к агенты отправляют в API гораздо большее количество текста, чем то, что вы им пишете. Для использования в режиме чата подойдут пакеты и меньшего размера.
🤖 Для агентов (Claude-Code, Aider, Cursor)¶
Если нужен максимум качества -
gpt-5.5Если важен баланс -
glm-5.1Что то попроще -
qwen3_235b
/llama
llama8b— Компактная модель на 8 млрд параметров, оптимальна для очень простых задач, где нужны низкие издержки.llama70b— Старшая модель Llama с 70 млрд параметров, позволяющая генерировать качественный текст.
/glm
NEWglm-5.1— Сбалансированная модель от Zhipu, сильна в китайском и английском языках, поддержка длинного контекста (до 1M токенов). Хороший выбор для извлечения информации из больших документов и RAG-систем. Очень хороша в агентном кодировании, особенно в сочетании со своей стоимостью.
/gpt
gpt-4.1— Превосходно подходит для генерации сложных логических текстов, и интеграции в сервисы. Хорошо будет работать в простых агентных системах, не требующих написания сложного кода.gpt-5— Последнее поколение моделей OpenAI, будет отличным выбором для использования в Claude Code, других мультиагентных системах или выполнения бизнес задач.NEWgpt-5.5— Лучшая из пятой серии. Улучшена точность следования инструкциям и уменьшено количество «галлюцинаций» в коде. Оптимальна для агентов, работающих с большими кодобазами, где важна согласованность правок. Имеет соответствующую стоимость.
/deepseek
deepseek-R1— Подойдет для выполнения простых задач и анализа, не сложной классификации, например обработки клиентских запросов для последующего перевода на поддержку.deepseek-V3— Улучшенная версия от этого производителя, для сложного анализа и генерации более качественного текста: анализ документов, генерации небольших статей.NEWdeepseek-V4— Флагманская модель с усиленной архитектурой MoE (Mix of Experts). Превосходит V3 в многошаговом рассуждении (CoT) и планировании задач.
/qwen
qwen3_30b— Баланс между качеством и экономичностью, заточена под диалог и контекстную генерацию, подойдет для парсинга входящих данных или легких помошников бизнеса.qwen3_235b— Тяжелая модель, лучшая по соотношению цена/качество, имеет самые большие пакеты. Подойдет для автоматизации, анализа и поддержки выполнения бизнес задач, использования в не самых сложных агентных системах.NEWqwen3_397b— Флагманская модель Qwen с 397 млрд параметров. Превосходит 235b в многоязычном коде, сложном рассуждении и следовании инструкциям при длинном контексте.
Примеры запросов:¶
Curl (Linux):
curl -X POST "https://inference.waw0.amvera.ru/v1/chat/completions" \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4.1",
"messages": [
{
"role": "user",
"content": "Hi, how are you?"
}
]
}'
Python:
from openai import OpenAI
client = OpenAI(
base_url="https://inference.waw0.amvera.ru/v1",
api_key="YOUR_API_KEY",
)
completion = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "5+7=?"}],
)
print(completion.choices[0].message.content)
Javascript:
import OpenAI from 'openai';
const client = new OpenAI({
baseURL: 'https://inference.waw0.amvera.ru/v1',
apiKey: 'YOUR_API_KEY',
});
const stream = await client.chat.completions.create({
model: 'qwen3_235b',
messages: [{ role: 'user', content: '5+7=?' }],
stream: true,
});
for await (const chunk of stream) {
const content = chunk.choices[0]?.delta?.content || '';
process.stdout.write(content);
}
Подключние к Claude Code¶
Установка¶
Windows:¶
Установите Node.js (v18+) - скачайте установщик с сайта.
Установите Git - скачайте установищик с сайта.
Разрешите выполение скриптов:
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
Установите Claude Code
npm install -g @anthropic-ai/claude-code
Проверьте установку
claude --version
Linux:¶
Установите Node.js (v18+) через менеджер пакетов или с сайта.
Установите Claude Code
npm install -g @anthropic-ai/claude-code
Проверьте установку
claude --version
Конфигурация API и выбор моделей для Claude Code¶
Windows (PowerShell)¶
Выполните в PowerShell:
[Environment]::SetEnvironmentVariable("ANTHROPIC_AUTH_TOKEN", "YOUR_API_KEY", "User")
[Environment]::SetEnvironmentVariable("ANTHROPIC_BASE_URL", "https://inference.waw0.amvera.ru", "User")
[Environment]::SetEnvironmentVariable("ANTHROPIC_DEFAULT_HAIKU_MODEL", "gpt-5", "User")
[Environment]::SetEnvironmentVariable("ANTHROPIC_DEFAULT_SONNET_MODEL", "gpt-5", "User")
[Environment]::SetEnvironmentVariable("ANTHROPIC_DEFAULT_OPUS_MODEL", "gpt-5", "User")
Важно: После установки переменных окружения необходимо закрыть и заново открыть PowerShell.
Linux / macOS¶
Добавьте следующие строки в файл ~/.bashrc или ~/.zshrc:
export ANTHROPIC_AUTH_TOKEN="YOUR_API_KEY"
export ANTHROPIC_BASE_URL="https://inference.waw0.amvera.ru"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="gpt-5"
export ANTHROPIC_DEFAULT_SONNET_MODEL="gpt-5"
export ANTHROPIC_DEFAULT_OPUS_MODEL="gpt-5"
Примените изменения:
source ~/.bashrc
Интеграция с LangChain/LangGraph¶
Установите библиотеку для интеграции.
pip install langchain langchain-amvera
Код интеграции
from langchain_amvera import AmveraLLM
from dotenv import load_dotenv
import os
load_dotenv()
# Поддерживаемые модели: llama8b, llama70b, gpt-4.1, gpt-5
llm = AmveraLLM(model="llama70b", api_token=os.getenv("AMVERA_API_TOKEN"))
response = llm.invoke("Объясни принципы работы нейросетей простым языком")
print(response.content)
Файл .env:
AMVERA_API_TOKEN=your_amvera_token_here
Подробная информация про адаптер для LangChain/LangGraph по ссылке https://pypi.org/project/langchain-amvera/
Интеграция с n8n¶
С 4 октября 2025 года Amvera LLM Inference API доступен как комьюнити-нода в n8n.
Для установки убедитесь, что ваша версия n8n поддерживает Community Nodes. Для этого перейдите в настройки n8n (Ваша аватарка -> Settings).
Если вы увидите вкладку Community Nodes - переходите в нее и устанавливаете ноду n8n-nodes-amvera-inference.
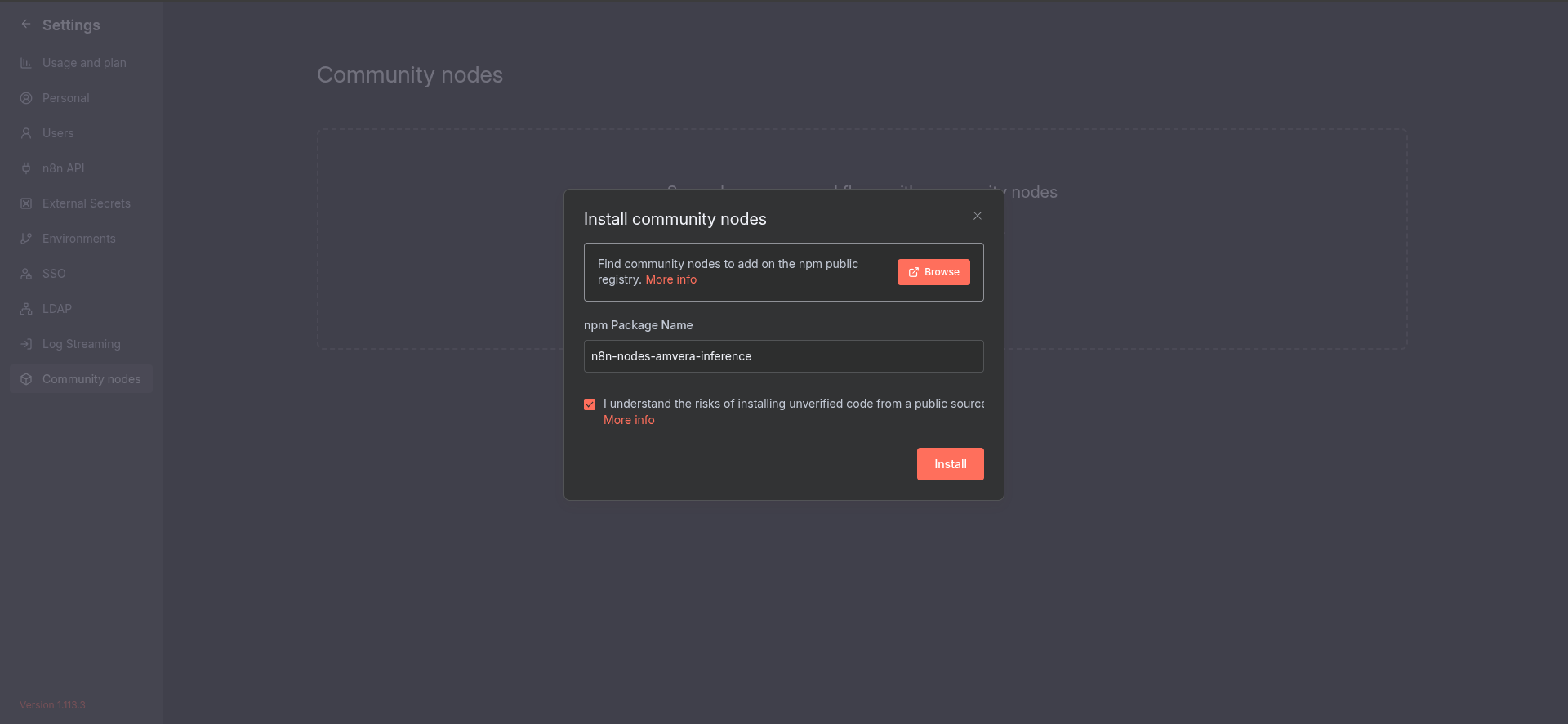
Если вкладки нет - попробуйте обновить версию n8n во вкладке «Конфигурация» и добавить переменную окружения
N8N_COMMUNITY_NODES_ENABLEDв значенииtrue
Установка комьюнити-ноды может занять до 10 минут. Если вы получаете ошибку, надо просто подождать. Повторной установкой вы можете прервать текущий процесс установки ноды.
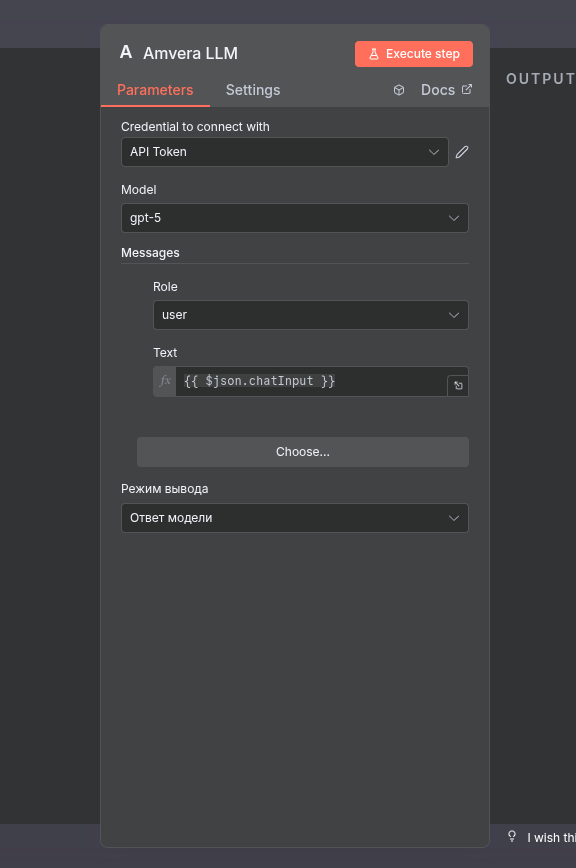
Базовые настройки ноды¶
Для работы с нодой необходимо создать Credentials в ее настройках и выбрать модель, создать минимум одно сообщения (system, user или assistant).
Режимы вывода¶
Всего поддерживается 2 режима вывода:
Ответ модели: выводится только ответ модели
JSON: выводится весь JSON Raw (весь ответ Amvera LLM Inference API)